
[projects] kor-eng translator-ver1
수정 로그: 문장 토큰화 방식을 기존 단어 빈도수 -> 형태소 분석을 마친 후 단어 빈도수 분석 방식으로 수정했습니다.
1. 영어 문장 정규화
Penn Treebank Tokenizer은 영어 문장의 구두점과 특수 문자를 구분하는 표준 토큰화 방법입니다.
Treebank Tokenizer의 규칙은 다음과 같습니다.
- hyphen(-)으로 구성된 단어는 하나로 유지한다.
- apostrophe(‘)으로 구성되 단어는 분리한다.
Treebank Tokenizer를 정규화 과정에 접목한 결과는 다음과 같습니다.
from unidecode import unidecode
from nltk.tokenize import TreebankWordTokenizer
import re
tree = TreebankWordTokenizer()
def reg_eng(sentence):
sentence = unidecode(sentence.lower().strip())
sentence = re.sub(r"([,.?!'])", r" \1", sentence)
sentence = re.sub(r'[" "]+', " ", sentence)
sentence = re.sub(r"[^a-zA-Z가-힣,'.?!]+", " ", sentence)
sentence = " ".join(tree.tokenize(sentence))
return sentence
tgt_raw[:5]
“i ‘m glad to hear that , and i hope you do consider doing business with us .”,
“i ‘m definitely thinking about it , but i have some queries to ask you .”,
“in today ‘s world , one in every five families has either a cat , dog , or both .”,
“when you tell them , we ‘ll take care of their child .”,
‘ok , how about for swimming ?’
2. 한국어 문장 정규화
Mecab 형태소 분석기는 한글 문장을 개별 단어와 토큰으로 구분짓는 널리 쓰이는 표준화 방법입니다.
MeCab을 한국어 정규화 과정에 접목한 결과는 다음과 같습니다.
from eunjeon import Mecab
m = Mecab()
def reg_kor(sentence):
sentence = sentence.strip()
sentence = re.sub(r"([,.?!])", r" \1", sentence)
sentence = re.sub(r'[" "]+', " ", sentence)
sentence = re.sub(r"[|ㄱ-ㅎ|ㅏ-ㅣ]+", " ", sentence)
sentence = " ".join(m.morphs(sentence))
return sentence
src_raw[:5]
‘그 말 을 들으니 기쁘 고 , 저희 와 거래 하 는 것 을 고려 해 주 셨 으면 합니다 .’,
‘확실히 생각 하 고 있 습니다 만 , 몇 가지 여쭤 보 고 싶 은 게 있 어요 .’,
‘오늘날 세계 5 가구 중 1 가구 는 고양이 나 개 또는 둘 다 를 키우 고 있 습니다 .’,
‘그 들 에게 말 하 면 , 저희 가 그 아이 들 을 돌볼 것 입니다 .’, ‘좋 아요 , 수영 은 어떤 가요 ?’
3. 결과
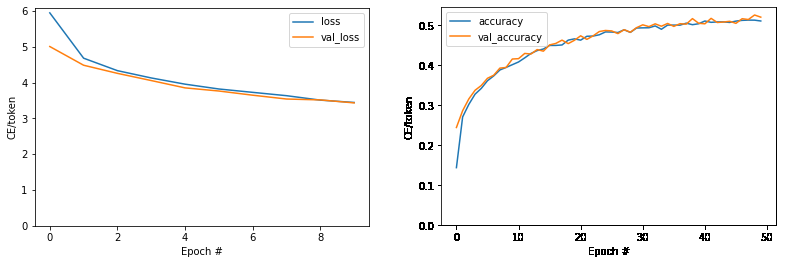
Before Tokenization
After Tokenization
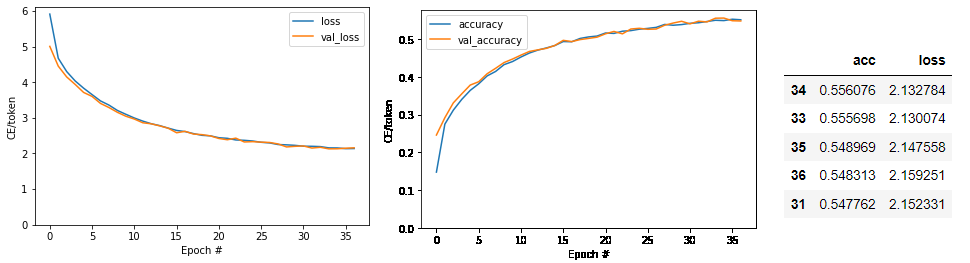
단어 단위로 토큰화 이후 임베딩한 ver-1.0 때보다,
형태소 단위로 토큰화한 이후 임베딩한 ver-1.1의 val_loss와 val_accuracy가 큰 폭으로 상승했음을 확인할 수 있다.
특히 ver-1.1으로 넘어올 때 val_accuracy가 0.50에서 0.55까지 0.05%p 상승한 만큼
한영 번역을 더 매끄럽게 진행할 수 있다.
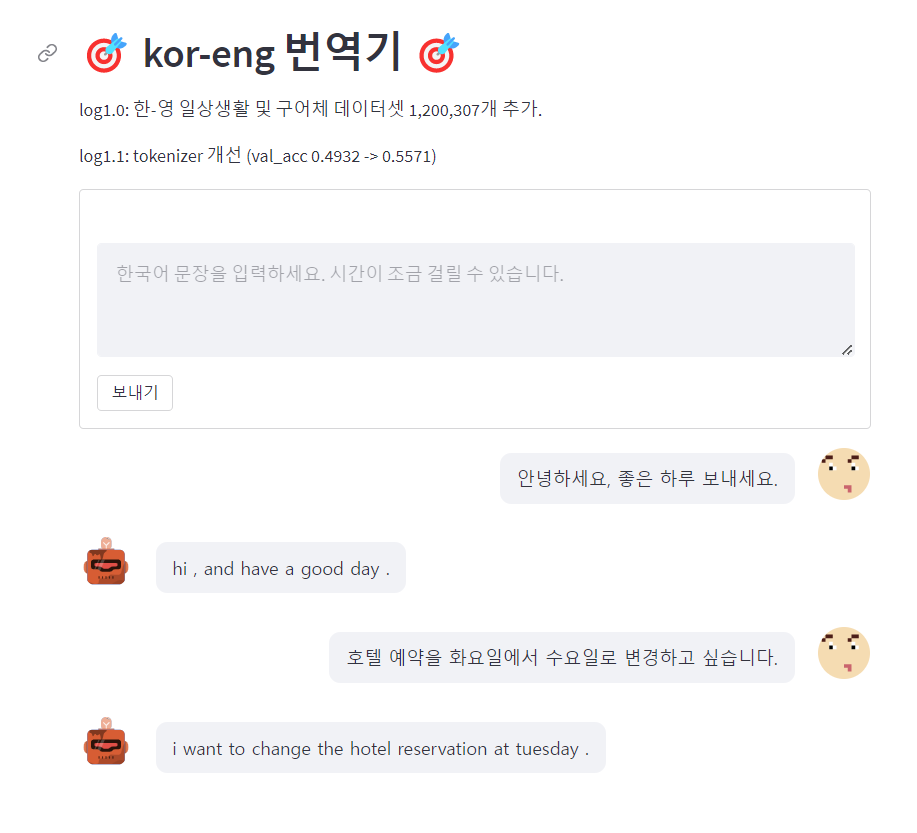
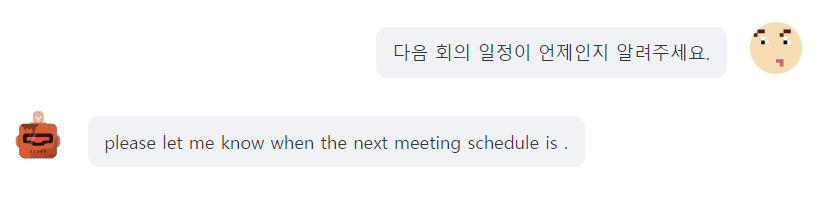
Streamlit에서 구현한 버전에서 한국어 문장 예제를 input으로 넣었을 때
확연히 이전보다 매끄러운 번역 수준을 보임을 확인할 수 있다.
댓글남기기