
[projects] kor-eng translator
Tensorflow tutorial을 참고하여 만든 일상생활 및 구어체 번역기 미니 프로젝트입니다.
Bidirectional GRU layer으로 임베딩한 sequence들을 참고해 다음에 나올 output을 예측하는 Attention model을 저장해
Streamlit application에 내장함수로 입력해 한국어 문장을 입력하면 번역한 영어 문장을 출력하는 시스템을 만들었습니다.
ipynb 파일 폴더: https://github.com/a2ran/kor-eng-translator
1. 데이터셋
사용 데이터셋: Ai-Hub 일상생활 및 구어체 한-영 번역 병렬 말뭉치 데이터
# json 데이터셋을 가져옵니다.
import json
with open(r'./aihub-data.json', encoding='utf-8') as f:
text = json.load(f)
print('한-영 대화 데이터셋 크기:', len(text['data']))
한-영 대화 데이터셋 크기: 1,200,307
# 예시
{'sn': 'ECOAR1A00922',
'data_set': '일상생활및구어체',
'domain': '해외고객과의채팅',
'subdomain': '숙박,음식점',
'en_original': 'We will send a notification message one day before your reservation.',
'en': 'We will send a notification message one day before your reservation.',
'mt': '예약 하루 전에 알림 메시지를 보내드립니다.',
'ko': '예약 하루 전에 알림 메시지를 보내드려요.',
'source_language': 'en',
'target_language': 'ko',
'word_count_ko': 6.0,
'word_count_en': 11.0,
'word_ratio': 0.545,
'file_name': '해외고객과의채팅_숙박,음식점.xlsx',
'source': '크라우드 소싱',
'license': 'open',
'style': '구어체',
'included_unknown_words': False,
'ner': None}
2. 전처리
비정형 데이터인 시퀀스 문장 데이터를 RNN layer으로 학습하기 위해서는 문장을 토큰화한 후 임베딩한 후
인코더 모델에 학습시킬 입력 변수 src,
Attention class에서 context_vector와의 가중평균을 decoder에 넘겨줄 타겟 변수 tgt_in,
Decoder에서 다음 단어를 예측하는데 사용할 레이블인 tgt_out 변수로 나누어주었습니다.
# 한국어 문장 정규화
# 문장의 시작과 끝을 '[START]', '[END]' 변수로 명시합니다.
import re
def reg_kor(sentence):
sentence = sentence.strip()
sentence = re.sub(r"([,.?!])", r" \1", sentence)
sentence = re.sub(r'[" "]+', " ", sentence)
sentence = re.sub(r"[|ㄱ-ㅎ|ㅏ-ㅣ]+", " ", sentence)
sentence = sentence.strip()
return sentence
def sos_eos_tokenize(sentence):
sentence = tf.strings.join(['[START]', sentence, '[END]'], separator = ' ')
return sentence
# Train, Validation 데이터셋을 zero-padded 토큰으로 변화합니다.
# Attention 모델에 사용하기 위해 한 단어의 텀을 가진 tgt_in, tgt_out 변수를 분리하고,
# tgt_in 변수와 context_vector인 src 변수를 묶어줍니다.
def text_processor(src, tgt):
src = src_text_processor(src).to_tensor()
tgt = tgt_text_processor(tgt)
tgt_in = tgt[:, :-1].to_tensor()
tgt_out = tgt[:, 1:].to_tensor()
return (src, tgt_in), tgt_out
train = train_raw.map(text_processor, tf.data.AUTOTUNE)
validation = validation_raw.map(text_processor, tf.data.AUTOTUNE)
3. 모델 Architecture
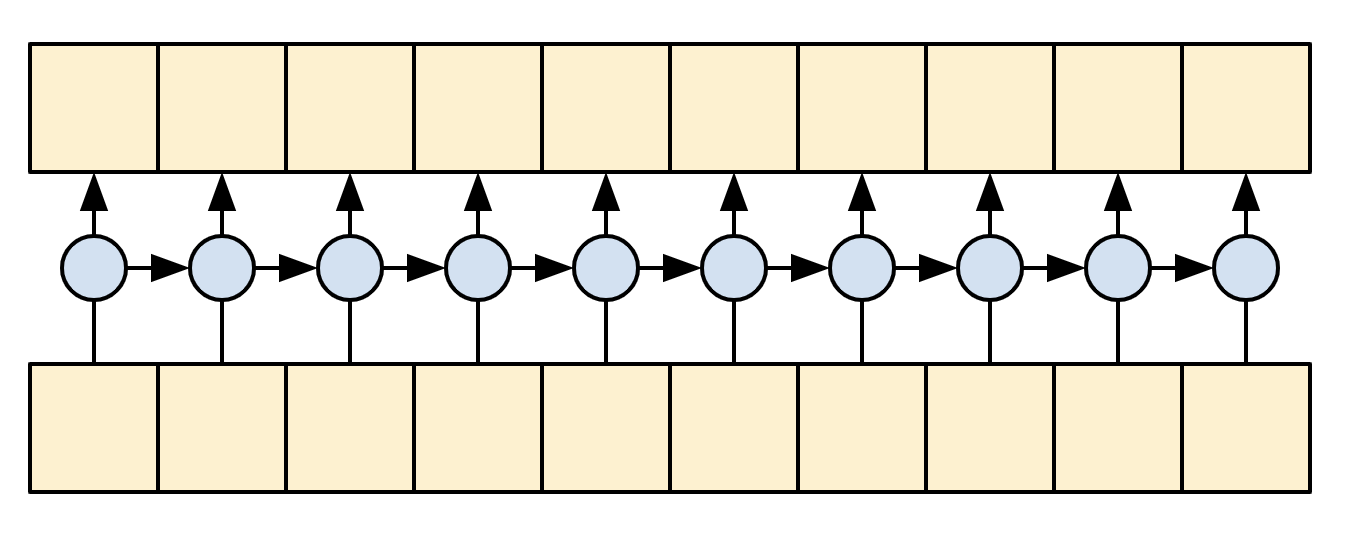
$1$. 인코더
 <div style="clear: both;"></div>
<div style="clear: both;"></div>
출처: nmt_with_attention.ipynb
인코더의 목적: 디코더가 문장에 나올 다음 단어를 예측할 때 참고할 context vector 만들기
- 토큰화한 문장을 임베딩한다.
- 임베딩화한 문장을 Bidirectional GRU layer으로 RNN 네트워크를 구축한다
- attention class에 해당 context_vector를 넘겨준다.
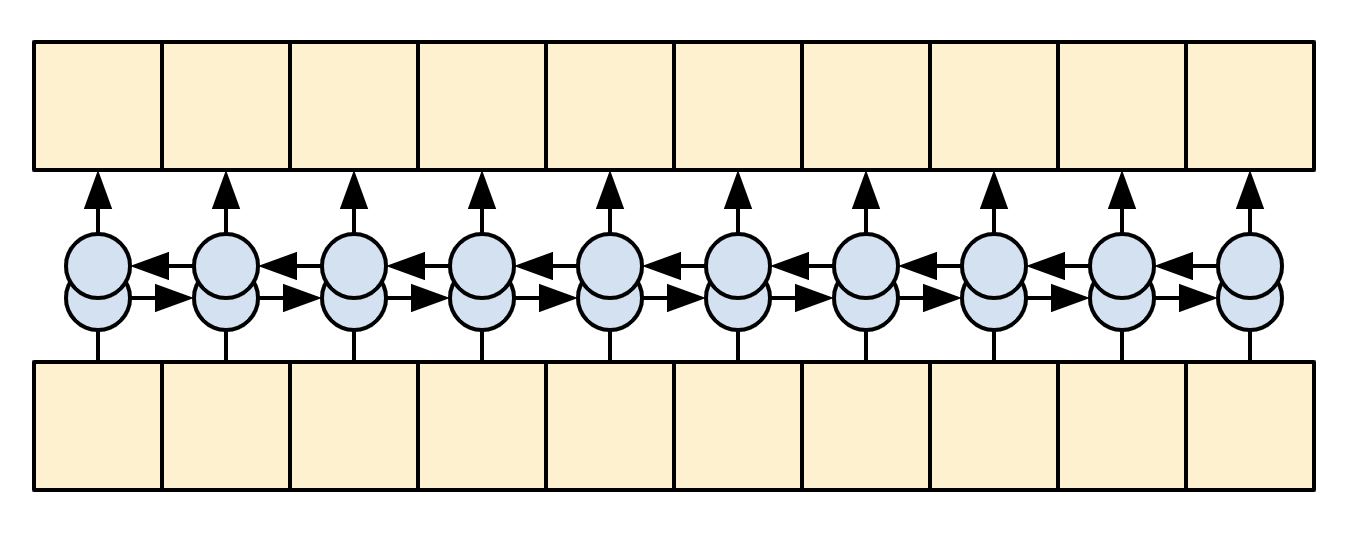
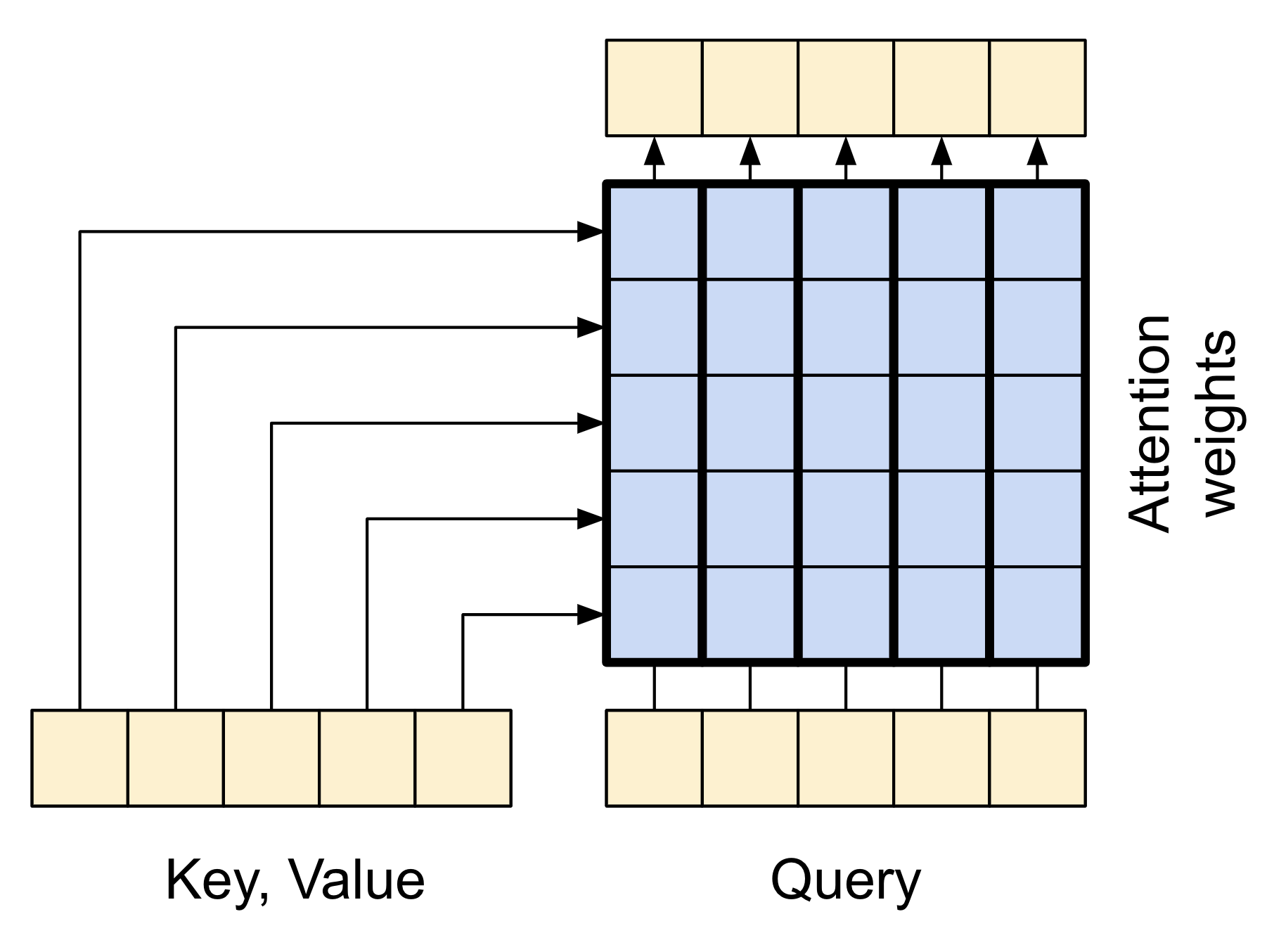
$2$. Attention layer
 <div style="clear: both;"></div>
<div style="clear: both;"></div>
출처: nmt_with_attention.ipynb
Attention layer은 Decoder가 예측할 때 Encoder의 정보를 확인할 수 있게 합니다.
Attention layer은 Encoder의 결과값인 context vector와 query vector의 가중 평균 데이터를 Decoder에 넘겨줍니다.
$3$. 디코더
 <div style="clear: both;"></div>
<div style="clear: both;"></div>
출처: nmt_with_attention.ipynb
Decoder는 문장에서 다음에 나올 토큰을 예측합니다.
- 예측 토큰 이전까지 나온 문장을 GRU layer으로 처리합니다.
- 해당 정보를 query_vector으로 처리해 Attention layer에서 인코더의 결과값을 참고합니다.
- 위 정보들을 토대로 다음에 나올 단어를 예측합니다.
4. 모델 학습
번역기 Translator 학습은 다음과 같은 과정으로 진행됩니다.
- 앞서 정의한 encoder, decoder 함수로 src, tgt 문장을 process합니다.
- query의 RNN output을 참고하여 attention class의 context vector를 불러옵니다.
- context vector와 tgt_out의 t-1 시점 hidden-state인 tgt-in 벡터로 다음 토근에 대한 logit prediction을 세웁니다.
# Train할 번역기 모델을 구축합니다.
class Translator(tf.keras.Model):
@classmethod
def add_method(cls, fun):
setattr(cls, fun.__name__, fun)
return fun
def __init__(self, units, src_text_processor, tgt_text_processor):
super().__init__()
encoder = Encoder(src_text_processor, units)
decoder = Decoder(tgt_text_processor, units)
self.encoder = encoder
self.decoder = decoder
def call(self, inputs):
context, x = inputs
context = self.encoder(context)
logits = self.decoder(context, x)
try:
del logits._keras_mask
except AttributeError:
pass
return logits
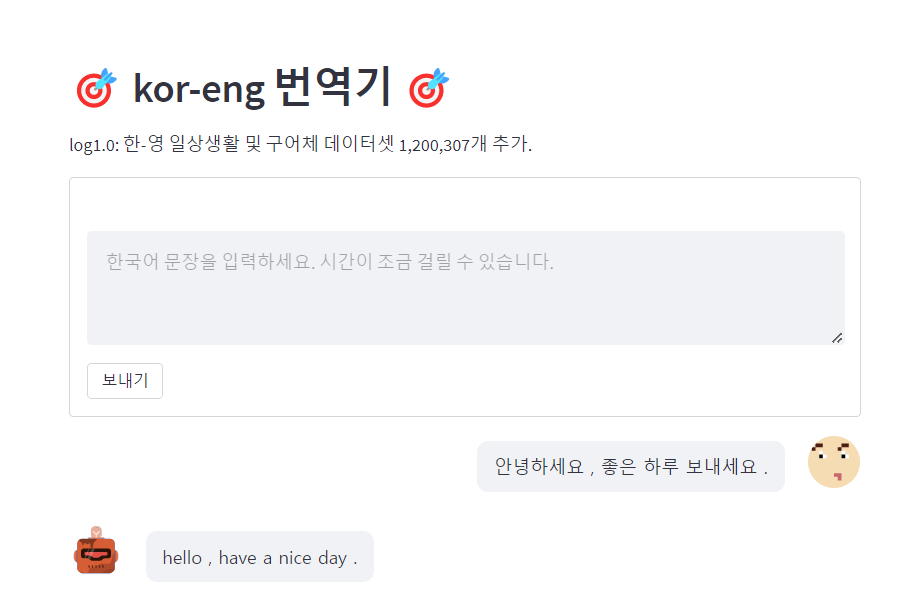
5. Streamlit 웹페이지 구축
Streamlit 라이브러리는 파이썬 환경에서 간단하게 머신러닝 함수를 내장한 웹 어플리케이션을 구축해 데모를 실험할 수 있도록 하는 서비스입니다.
tf.save_model함수로 저장한 model을 불러와 한국어 문장을 입력값으로 넣으면 번역된 영어 문장을 출력하는 웹 서비스 모형을 만들어 보고자 합니다.
import streamlit as st
from streamlit_chat import message
import tensorflow as tf
import re
#페이지 설정
st.set_page_config(
page_title = "kor-eng-번역기",
page_icon = "chart_with_upwards_trend",
layout = "centered",
initial_sidebar_state = "collapsed",
menu_items = {
'Get Help': 'https://www.a2ran.github.io',
'About': "kor-eng 번역기입니다."
}
)
# 모델 불러오기
def cached_model():
model = tf.saved_model.load('kor-eng-translator')
return model
model = cached_model()
# 번역된 문장이 들어갈 series 정의
if 'eng' not in st.session_state:
st.session_state['eng'] = []
# 번역할 문장이 들어갈 series 정의
if 'kor' not in st.session_state:
st.session_state['kor'] = []
# 유저가 전송버튼을 누른 후
if submitted and inp:
inp = reg_kor(inp)
result = model.translate([inp])
answer = result[0].numpy().decode().strip()
st.session_state.kor.append(inp)
st.session_state.eng.append(answer)
# 결과값 웹사이트에 표시
for _ in range(len(st.session_state['kor'])):
message(st.session_state['kor'][_], is_user = True, key = str(_) + '_한글')
if len(st.session_state['eng']) > _:
message(st.session_state['eng'][_], key = str(_) + '_영어')
결과
출처
- https://www.tensorflow.org/text/tutorials/nmt_with_attention
- https://aihub.or.kr/aihubdata/data/view.do?currMenu=115&topMenu=100&aihubDataSe=realm&dataSetSn=71265
댓글남기기