
[nlp_paper] Seq2Seq Paper Review
DSL 논문 스터디 6기 손예진님이 발제하신 내용을 기반으로 작성했습니다.
Introduction
Seq2seq neural network model encodes an input sequence, converts it as a fixed-length vector representation, and decodes it to produce an output sequence.
Seq2seq is commonly used to translate sequence data such as
Machine Translation, Speech Recognition, and QA.
Model Architecture
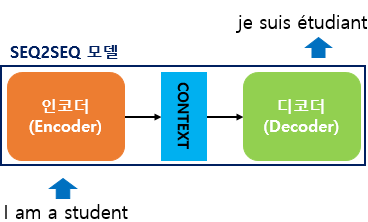
Seq2seq model is consisted of two major LSTM architectures:
Encoder Architecture
Decoder Architecture
Encoder cell inputs tokenized sequence data and summerizes it into one single hidden-state numerical vector (the context vector)
Decoder cell receives the context vector and predicts the probability of $y_t$ given the value of the hidden LSTM cell $t-1$ and input vector $t$ until the end of sentence <EOS> token.
Paper Review
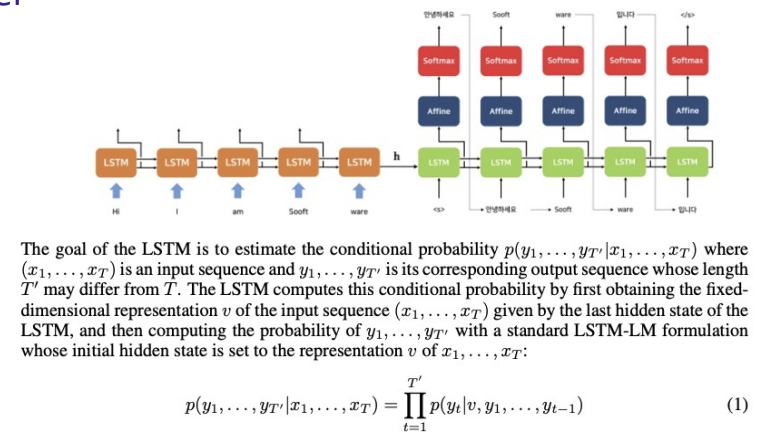
To summarize, Seq2seq model utilizes depth-4 lstm model. Each layer contains over 1,000 cells and 1,000 dimensional word embeddings.
Its input vocab is 160,000 sized, and output vocab is 80,000 sized vectors.
The model used a naive softmax onto each 80,000 vocabs on every outputs.
Reversed Source Sentences

Seq2seq model also experiemnted an reversed src (source) sentences. When the source sentences are reversed and the tgt (target) sentences remain the same, the distance between the initial src token and the tgt token become closer.
This has a significan impact since the Seq2seq model decodes data based on sequential data hidden state $t-1$ and input vector $t$. Since the prediction accuracy of the initial vectors improved, the overall performance also gained more accuracy.
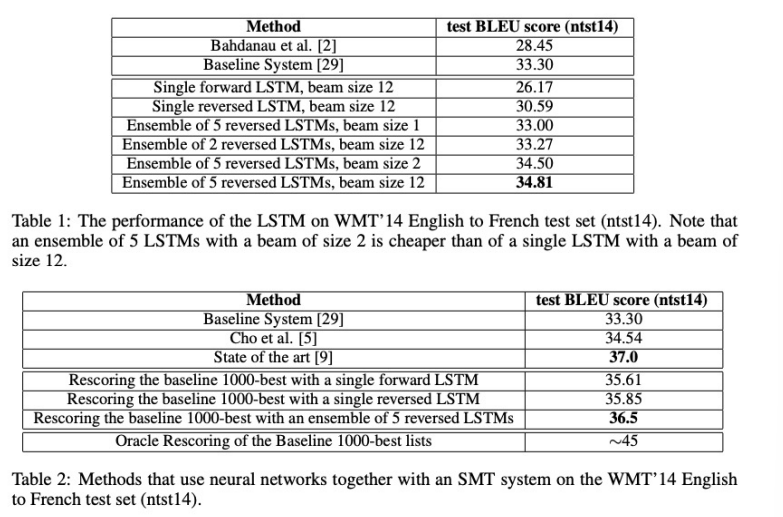
Experimental Results
The experimental Results are summarized as followed.
The BLEU score evaluates the quality of text generated by machine translation systems. It compares the generated text to human translated text by calculating the n-gram overlap.
Seq2seq LSTM model shows remarkable improvement from traditional machine translation models although it is way more cheaper than these SMTs.
Limitations & Improvements
Seq2seq model has two major problems.
- The Encoder cell summarizes all its information into a single context vector. It results in significant information loss.
- LSTM is a RNN model. So, it has its chronic problem: vanishing gradient.
The first problem of Seqseq model, which comes from summerizing information into a single vector, is improved on the next model : attention + Seq2seq which will be covered at the next post.
댓글남기기