
[nlp_paper] Attention is not Explanation Paper Review
- DSL 논문 스터디 6기 손예진님이 발제하신 내용을 기반으로 작성했습니다.
Attention
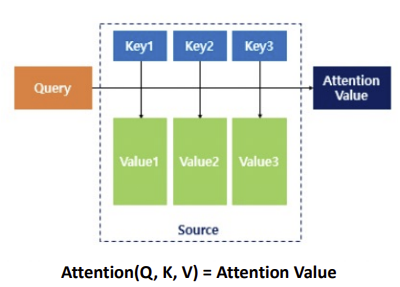
The Attention model works by a specific attention mechanism “Scaled Dot Product Attention”
$Attention(Q, K, V) = softmax(\frac{QK^T}{\sqrt(d_k)})$
Attention mechanism splits the input into three categories:
($Q$) for query (hidden-state at t decoder cell)
($K$) for key (hidden-state at every encoder cell $k$)
($V$) for value (hidden-state at every encoder cell $v$)
By calculating the Dot product of query $Q$ and key $K$, and scaling it by the square root of key $k$’s dimension,
The attention mechanism produce a score for each key value pair that indicates the importance of value $v$.
By computing scores for each value $v$, the Attention model is able to decide a particular important part of the src sentences it should attend to when making every predictions.
Is Attention Explainable?
Attention is not Explanation (Jain and Wallace; 2019, NAACL)

The Attention model has been known to have Explainability
since it can sort out important input tokens that affect the result of classification.
For instance, by highlighting important tokens in the source sentences,
one can find out if the model is designed as it was meant to be,
and use it to explain the result of the model.

However, there are several reported cases of attention model not properly repersenting the explainability of tokens.
Attention Calibration for Transformer in Neural Machine Translation (Lu et al., ACL; 2021) found out that some outputs (e.x. “Deaths”) were tokenized from negligible tokens such as [EOS].
Also, What does BERT look at? An Analysis of BERT’s Attention (Clark et al., BlackboxNLP; 2019 claims that most of attention results are tokenized from tokens such as [CLS], [SEP], Periods, and Commas.
So, there are several counterexamples to use Attention to explain models.
Paper Review
Main Opinion: Attention is not a faithful explanation to a model.
Attention model should satisfy following constraints to become explainable.
- Attention weights should be similar to other explainable methods such as Feature Importance.
- There should be only one attention for a single output.
Experiment 1-1
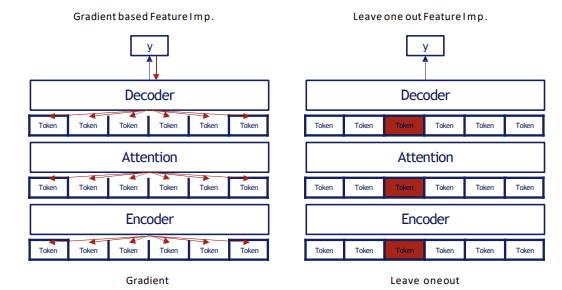
Experiment 1-1 explains correlation between Attention Weights and Feature Importance (Gradient/Leave One Out)
Gradient calculates how change in a particular token affects the predicted value.
$\tau_g$ = correlation between Gradient and Attention.
Leave One Out (LOO) calculates how excluding a particular token affects the overall performance of the model.
$\tau_{loo}$ = correlation between the output and attention
Result
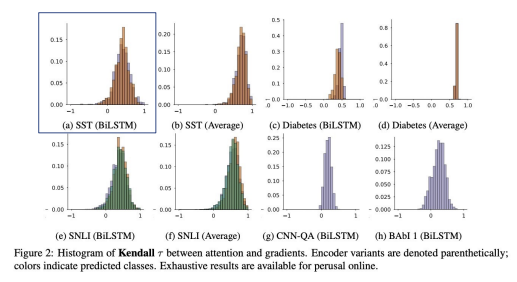
The correlation coefficient between Attention-Importance is lower than the Average value.
$\therefore$ Attention Weights have low correlation with Feature Importance.
Experiment 1-2
Experiment 1-2 explores the correlations between feature importance and attention weights.
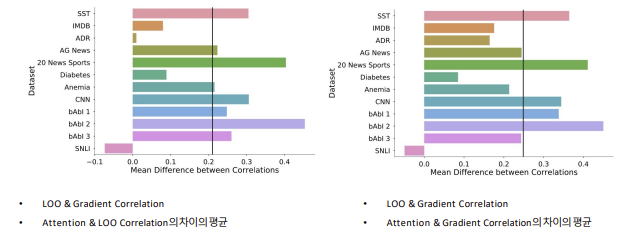
Result
The correlation between LOO & Gradient is significantly remarkable than the correlation between Attention & Importance (0.2 ~ 0.4)
Experiment 2
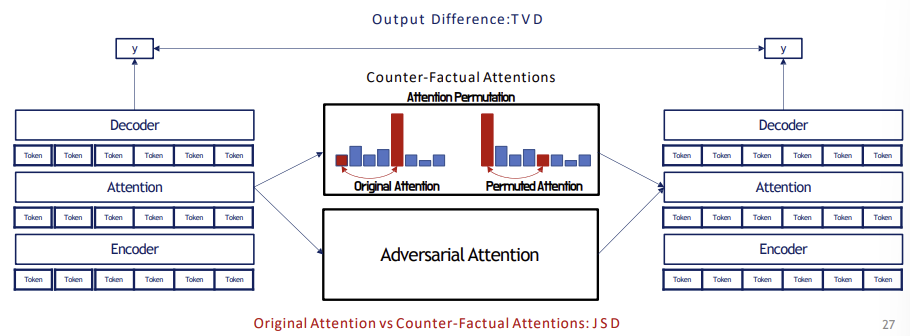
Experiment 2 explores if it is possible to create another attention that yields same output with original attention model.
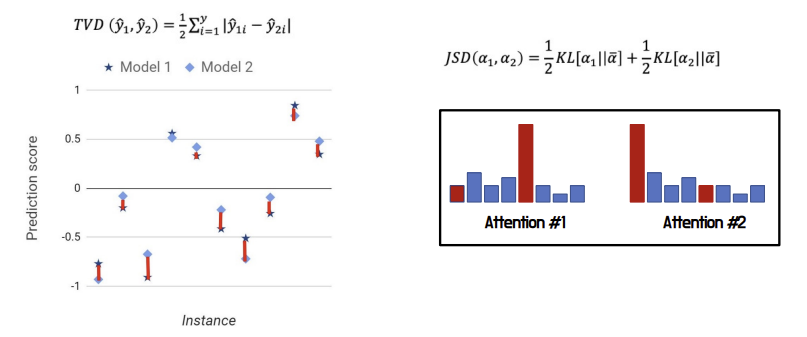
Total Variance Distance (TVD) calculates difference between outputs
Jensen Shannon Divergence (JSD) calculates difference between two distributions.
Counterfactual Attention is an attention model that yields same output with original attention model.
Experiment 2-1
Permutated Attention randomly permutates attention to calculate a total variance distance between original attention output and the permutated attention output.
Experiment 2-1 searches if the counterfactual attention can be built from an original model with a miniscule difference in output.
Result
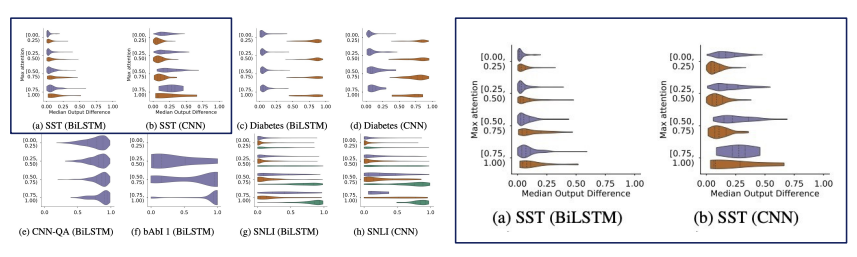
Above graphs are the median difference between the $y$ from the original attention and $y$ from permutation attention.
It is shown that there is no difference between permutated output and the original output.
Conclusion
Experiment 1 : Attention Weights is not related to Feature Importance.
However the correlation between Feature Importance is significant.
Experiment 2 : There can be multiple attention for a single output.
The difference between Adversarial attention with original attention is miniscule.
As a Result, Attention is not Explaination.
Source : https://arxiv.org/pdf/1902.10186.pdf
DSBA seminar material : http://dsba.korea.ac.kr/seminar/
댓글남기기