
[nlp_paper] Attention is not not Explanation Paper Review
- DSL 논문 스터디 6기 손예진님이 발제하신 내용을 기반으로 작성했습니다.
Attention is not Explanation
Jain and Wallace (2019, NAACL) proved in their thesis
that attention is not a faithful explanation to a model
due to the fact that:
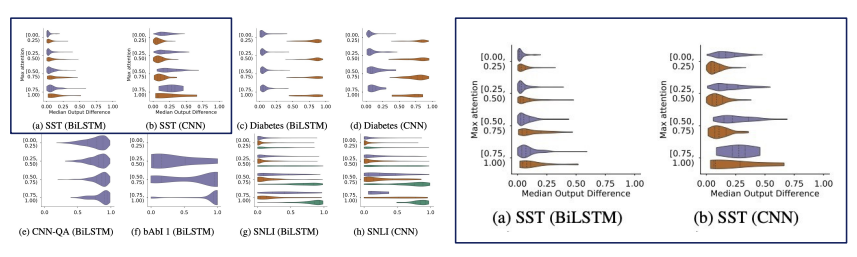
Experiment 1 : Attention Weights is not related to Feature Importance.
However the correlation between Feature Importance is significant.
Experiment 2 : There can be multiple attention for a single output.
The difference between Adversarial attention with original attention is miniscule.
Attention is not not Explanation
However, Wiegreffe and Pinter (2019) partially rebuked Jain and Wallace’s claim by acknowledging that Attention Weights is not related to Feature Importance,
but Experiment 2 on adversarial attention contains structural problem.
Attention model is not independent from other parameters. Wiegreffe stated that Jain’s experimentation did not fully consider Degree of Freedom since adjusting attention based on instances does not qualify independence.
Is Attention Useful in First Place?
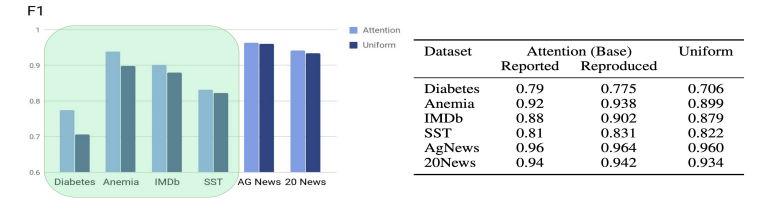
Wiegreffe first proved attention model’s usefulness by comparing the performance difference between the attention model and the base model (uiform model).
As a result, it is shown that attention takes a role on performance improvements.
Is Attention Robust in First Place?
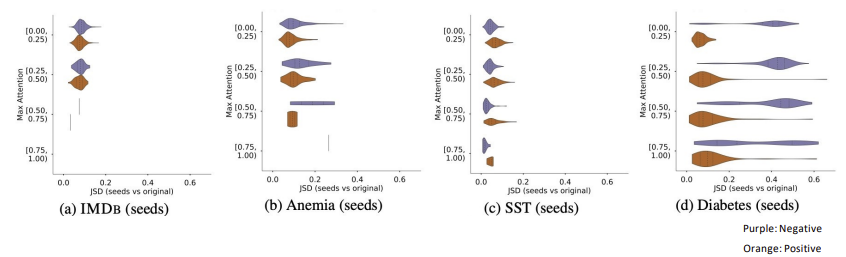
Wiegreffe hypothesized that if attention model is malleble regarding to the random seed, there is no need for testing adversarial attention model.
It is shown that attention model is robust and hard to manipulate despite changing its random seed.
Experiments

Attention : Each token’s attention score is calculated by attention parameters.
Context of Tokens : LSTM layer of each token’s context
Wiegreffe claims that to figure out the true value of the attention model, one should remove the context of tokens section and emphasize the attention section.
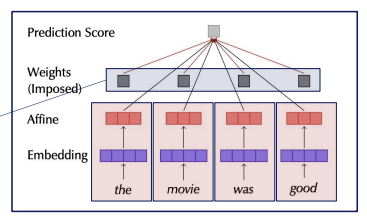
To remove the context of tokens section, Wiegreffe transformed LSTM layer into MLP layer of each tokens, and imposed weights on each tokens.
Results
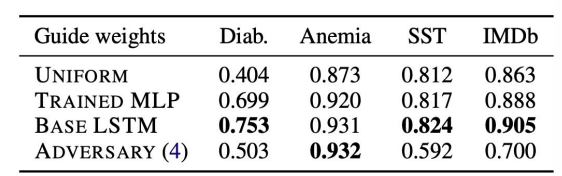
Wiegreffe trained the model via four attention weights.
- Uniform (base model)
- Base LSTM (attention freeze)
- Trained MLP
- Adversial attention
It is shown that uniform attention has the lowest performance among the models
-> attention models influence the performance of the model.
Trained MLP and base LSTM shows no significant difference.
Adversary attention’s performance is significantly worsened.
Conclusion
-
Attention improves the overal performance of the model since every attention model shows better performance than the uniform model.
-
Attention model is trainable without context since Trained MLP shows similar performance than the Base LSTM model.
-
Attention model is difficult to manipulate.
Source : https://arxiv.org/pdf/1902.10186.pdf
DSBA seminar material : http://dsba.korea.ac.kr/seminar/
댓글남기기