
Fashion MNIST dimensionality reduction
Fashion MNIST dataset
- 28*28 pixels(784 차원)
- label
- 0 T-shirt/top
- 1 Trouser
- 2 Pullover
- 3 Dress
- 4 Coat
- 5 Sandal
- 6 Shirt
- 7 Sneaker
- 8 Bag
- 9 Ankle boot
X_train, y_train, X_test, y_test 지정하기
# fashion data 6,000개 사용
# train : test = approximately 8 : 2
fashion = fashion.loc[:6000, :]
rnd = np.random.uniform(size = (len(fashion), )) < 0.8
train = fashion[rnd]
test = fashion[~rnd]
plt.figure(figsize = (15, 6))
for _ in range(1, 11):
plt.subplot(2, 5, _)
label = y_train.loc[_]
image = X_train.loc[_, :].values.reshape([28, 28])
plt.imshow(image, cmap = plt.get_cmap('gray'))
plt.title('Example: %d / Label: %d'%(_, label))
plt.show()

합리적인 잠재변수 개수 설정하기
cumul = []
cnt = 0
for _ in range(784):
cnt += pca.explained_variance_ratio_[_]
cumul.append(cnt)
plt.plot(range(1, 785), cumul)
plt.show()
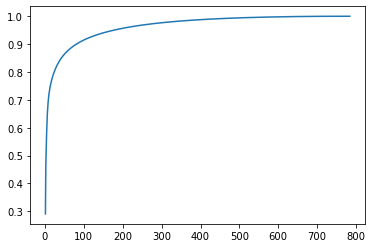
print(np.where(np.array(cumul) > 0.8)[0][0])
print(np.where(np.array(cumul) > 0.85)[0][0])
print(np.where(np.array(cumul) > 0.9)[0][0])
23
41
80
학습속도, 성능의 향상을 보이는지 확인
# 784-dimension XGBoost
from xgboost import XGBClassifier
start = time.time()
xgboost = XGBClassifier()
xgboost.fit(X_train, y_train)
print('train f1-score :',f1_score(y_train, xgboost.predict(X_train), average = 'weighted'))
print('test f1-score :',f1_score(y_test, xgboost.predict(X_test), average = 'weighted'))
print(f'{time.time() - start:.3f} seconds')
train f1-score : 1.0
test f1-score : 0.8753377072431694
73.660 seconds
# 41-dimension PCA-XGBoost
from xgboost import XGBClassifier
from sklearn.model_selection import GridSearchCV
start = time.time()
xgboost = XGBClassifier()
xgboost.fit(X_train_PCA, y_train)
print('train f1-score :',f1_score(y_train, xgboost.predict(X_train_PCA),
average = 'weighted'))
print('test f1-score :',f1_score(y_test, xgboost.predict(X_test_PCA),
average = 'weighted'))
print(f'{time.time() - start:.3f} seconds')
train f1-score : 1.0
test f1-score : 0.859548725797727
14.650 seconds
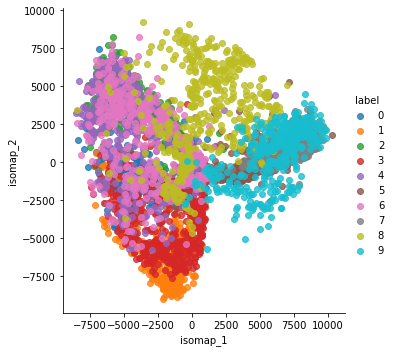
2차원으로 시각화
Isomap
from sklearn.manifold import Isomap
isomap = Isomap(n_neighbors = 5, n_components = 2,n_jobs = 4)
X_train_isomap = isomap.fit_transform(X_train)
X_train_isomap = pd.DataFrame(X_train_isomap).loc[:,0:1]
X_train_isomap = pd.concat((X_train_isomap, y_train), axis=1)
X_train_isomap.columns = ['isomap_1', 'isomap_2', 'label']
sns.lmplot(x='isomap_1',y='isomap_2',data=X_train_isomap,hue='label',
fit_reg=False)
plt.show()
t-SNE
from sklearn.manifold import TSNE
tsne = TSNE(n_components = 2, random_state=42) #4미만의 공간으로
X_train_tsne = tsne.fit_transform(X_train)
X_train_tsne=pd.DataFrame(X_train_tsne).loc[:,0:1]
X_train_tsne=pd.concat((X_train_tsne, y_train), axis=1)
X_train_tsne.columns=['tsne_1', 'tsne_2', 'label']
sns.lmplot(x = 'tsne_1',y = 'tsne_2',data=X_train_tsne,
hue = 'label',fit_reg = False)
plt.show()

댓글남기기