
koGPT2 fine-tuned 심리상담 챗봇
한국어 문장예측모델인 skt/kogpt2을 fine-tuning해
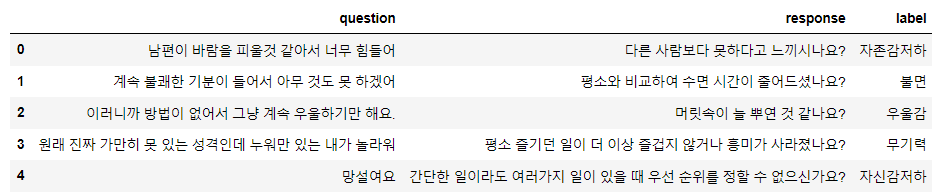
사용자가 심리상담 주제 관련 문장을 입력하면,
대화의 주제와 응답을 출력하는 챗봇 모델을 구축했습니다.
출처: 웰니스 대화 스크립트 데이터셋(AI Hub, 2019)
Kogpt2 모델 https://github.com/SKT-AI/KoGPT2
github repository link : https://github.com/a2ran/kogpt2-chatbot
Introduction

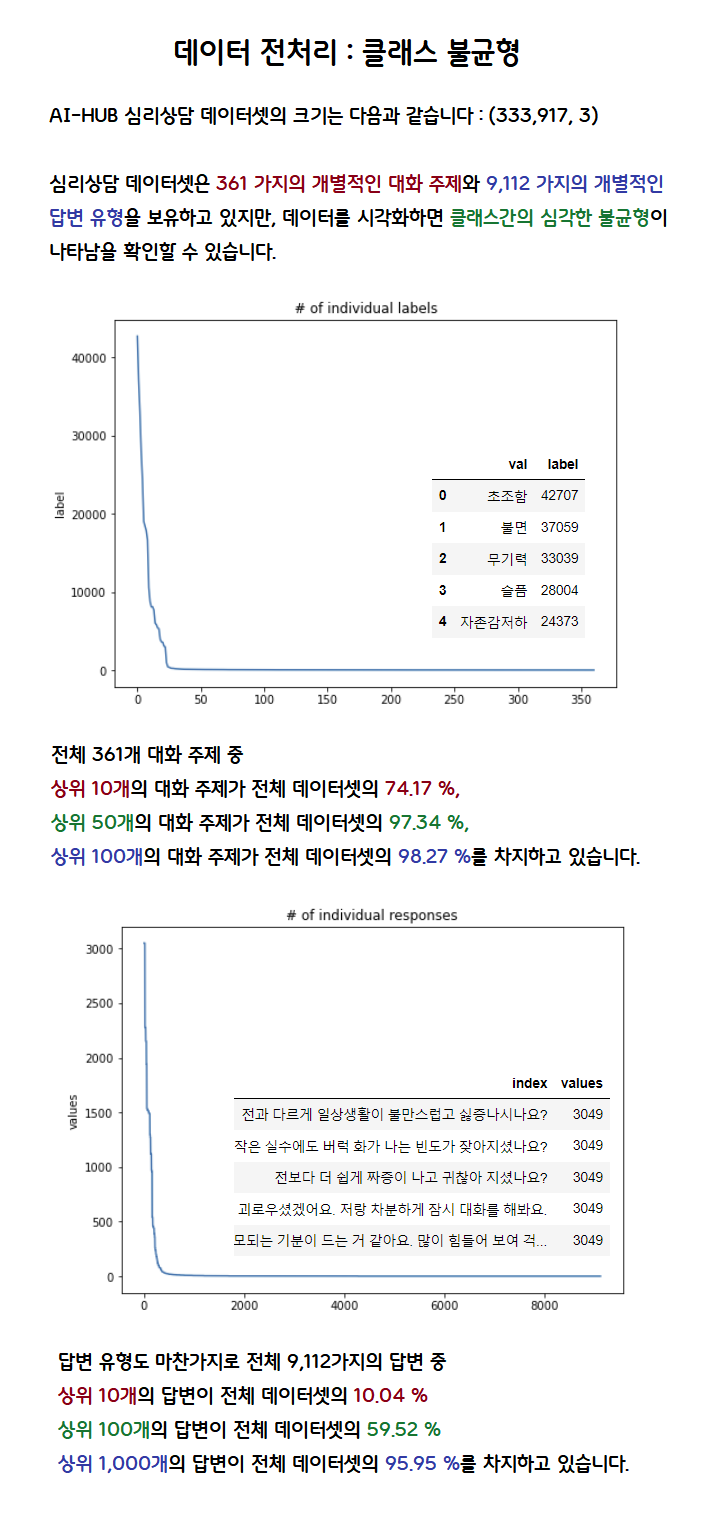
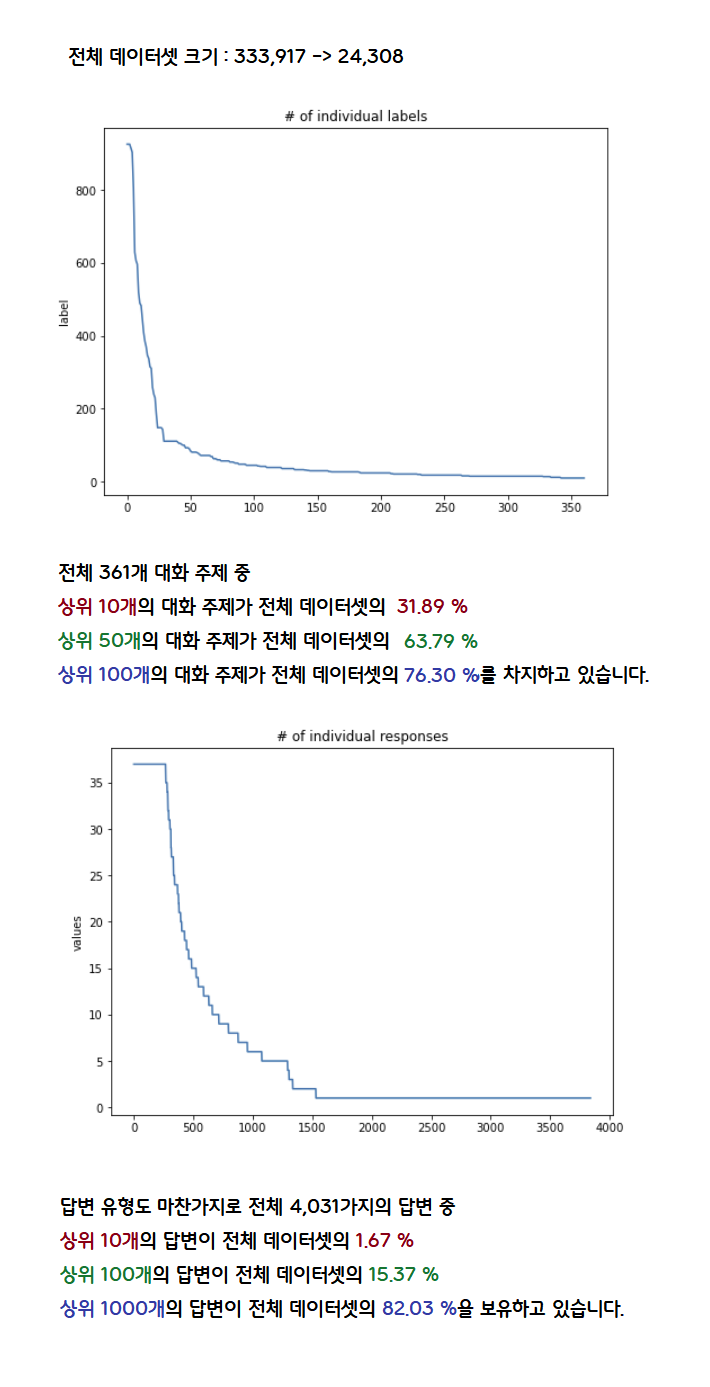
Class Imbalance


Tokenization

Codes
tokenizer = AutoTokenizer.from_pretrained('skt/kogpt2-base-v2', bos_token='</s>', eos_token='</s>', pad_token='<pad>')
model = TFGPT2LMHeadModel.from_pretrained('skt/kogpt2-base-v2', from_pt=True)
def tokenize_df():
# 질문, 레이블 응답 문장을 불러옵니다.
for question, label, response in zip(df.question.to_list(),
df.label.to_list(), df.response.to_list()):
# 문장의 BOS token : </s>
bos_token = [tokenizer.bos_token_id]
# 문장의 EOS token : </s>
eos_token = [tokenizer.eos_token_id]
#문장 구조 : BOS + 질문 + (토큰으로 구분) + 레이블 + (토큰으로 구분) + 응답 + EOS
sentence = tokenizer.encode('<unused0>' + question + '<unused1>' + label + '<unused2>' + response)
yield bos_token + sentence + eos_token
batch_size = 32
# def 함수를 적용한 tf dataset을 만듭니다.
dataset = tf.data.Dataset.from_generator(tokenize_df, output_types = tf.int32)
# batch에서 가장 긴 문장을 기준으로 zero-padding을 진행합니다.
dataset = dataset.padded_batch(batch_size = batch_size, padded_shapes=(None,),
padding_values = tokenizer.pad_token_id)
for batch in dataset:
break

Train Model
#Hyperparameters
EPOCHS = 20
adam = tf.keras.optimizers.Adam(learning_rate = 3e-5, epsilon=1e-08)
steps = len(df) // batch_size + 1
# dataset을 batch_size으로 나눈 batch에서 loss를 계산한 후
# tf.GradientTape으로 gradient을 계산하고
# 계산한 gradient을 통해 adam(model)을 업데이트합니다.
for epoch in range(EPOCHS):
train_loss = 0
try:
for batch in tqdm.notebook.tqdm(dataset, total = steps):
try:
with tf.GradientTape() as tape:
result = model(batch, labels = batch)
loss = result[0]
batch_loss = tf.reduce_mean(loss, -1)
grads = tape.gradient(batch_loss, model.trainable_variables)
adam.apply_gradients(zip(grads, model.trainable_variables))
train_loss += batch_loss / steps
except:
pass
except:
pass
# save fine-tuned tokenizer & model
tokenizer.save_pretrained('chatbot')
model.save_pretrained('chatbot')
Result

# load fine-tuned model
tokenizer = AutoTokenizer.from_pretrained('chatbot', bos_token='</s>', eos_token='</s>', pad_token='<pad>')
model = TFGPT2LMHeadModel.from_pretrained('chatbot')
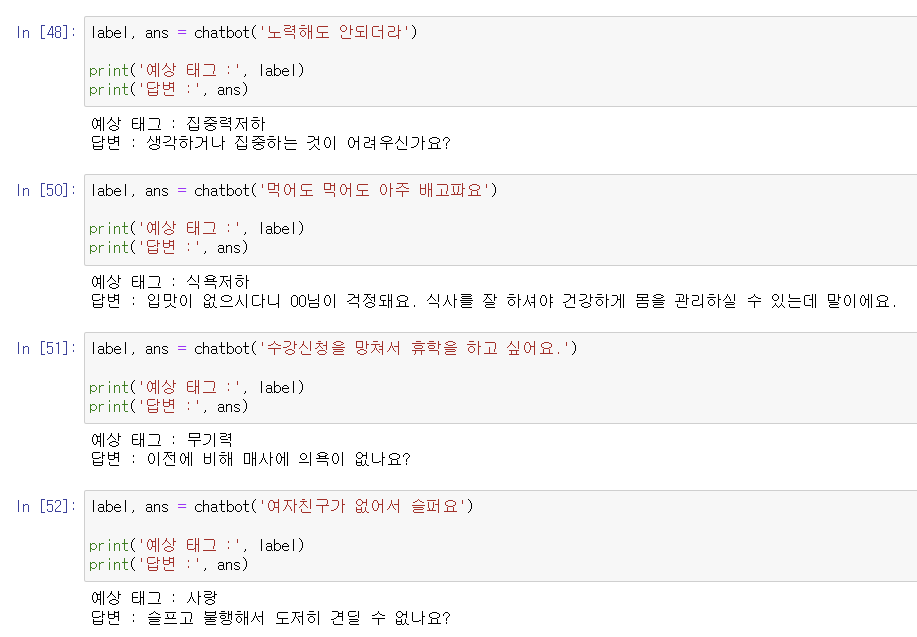
def chatbot(text):
# input sentence : "질문" / 레이블 + 응답
sentence = '<unused0>' + text + '<unused1>'
tokenized = [tokenizer.bos_token_id] + tokenizer.encode(sentence)
tokenized = tf.convert_to_tensor([tokenized])
# 질문 문장으로 "레이블 + 응답" 토큰 생성
result = model.generate(tokenized, min_length = 50, max_length = 200, repetition_penalty = 0.8,
do_sample = True, no_repeat_ngram_size = 3, temperature = 0.01,
top_k = 5)
output = tokenizer.decode(result[0].numpy().tolist())
response = output.split('<unused1> ')[1]
# 레이블 토큰 출력
label = response.split('<unused2> ')[0]
# 응답 토큰 생성
response = response.split('<unused2> ')[1].replace('</s>', '')
return label, response
Revision

댓글남기기