
태그 데이터 원-핫 인코딩으로 처리
리스트, string 형태로 있는 태그 series를 전처리 후 0과 1의 숫자열 데이터로 변환합니다.
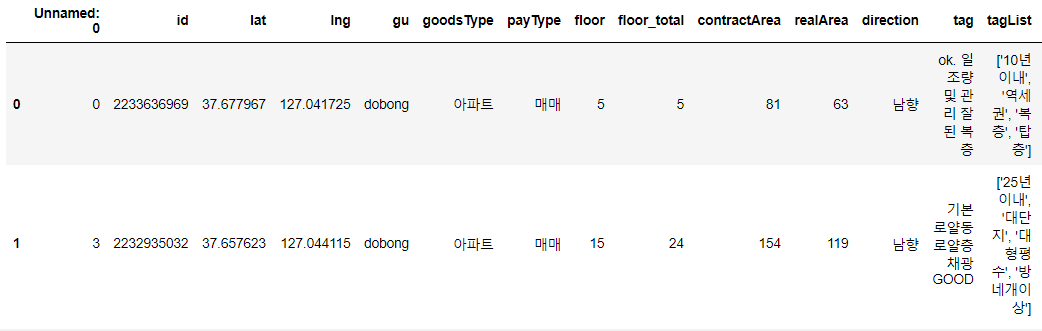
데이터셋 불러오기
house = pd.read_csv('house.csv')
house.head(2)
# X 정의
X_features = house.drop(['deposit'], axis = 1)
tagList 데이터
해당 데이터에서는 태그 데이터가 list 형태 string으로 저장되어 있습니다.
np.unique(X_features.loc[:, 'tagList'])
# 결과
array(["['10년이내', '1층', '관리비10만원이하', '남동향']",
"['10년이내', '1층', '관리비10만원이하', '엘리베이터']",
"['10년이내', '1층', '관리비10만원이하', '주차가능']", ...,
"['화장실한개', '소형평수', '방두개']", "['화장실한개', '소형평수', '방세개']", '[]'],
dtype=object)
정규표현식
정규표현식을 사용해 의미있는 단어를 제외한 나머지 Punctuation을 제거하고,
태그 단위로 변환한 리스트를 반환합니다.
import re
def regdex(sentence):
sentence = re.sub(r"([,.?'!])", r"", sentence[1:-1])
sentence = sentence.split(' ')
return sentence
tag = np.array([regdex(X_features['tagList'][_]) for _ in range(len(X_features['tagList']))])
결과는 다음과 같습니다. 성공적으로 리스트 형태 token으로 변환되었습니다.
tag[:3]
# 결과
array([list(['10년이내', '역세권', '복층', '탑층']),
list(['25년이내', '대단지', '대형평수', '방네개이상']),
list(['25년이상', '융자금적은', '올수리', '화장실한개'])], dtype=object)
One-Hot Encoding
먼저 tag 내 단어들을 전부 re 칼럼에 펼쳐 unique한 단어와 갯수를 파악합니다.
# tagList내 단어 전부를 하나의 리스트로 extend한다.
re = []
for j in tag:
re.extend(j)
# tagList내 독립적인 단어
np.unique(re)
# 결과
array(['', '10년이내', '15년이내', '15대이상', '1층', '25년이내', '25년이상', '2년이내',
'4년이내', 'CCTV', '고층', '관리비10만원이하', '관리비20만원이하', '관리비30만원이하',
'관리비40만원이하', '관리비50만원이하', '관리비60만원이하', '관리비70만원이하', '관리비80만원이하',
'급매', '남동향', '남서향', '남향', '대단지', '대형평수', '동향', '마당', '무보증',
'방네개이상', '방두개', '방세개', '방한개', '베란다', '보안', '보일러교체', '복층', '북동향',
'북서향', '북향', '붙박이장', '비디오폰', '서향', '세대당', '세대당1대', '세대분리', '세안고',
'소형전월세', '소형평수', '신발장', '싱크대', '에어컨', '엘리베이터', '역세권', '올수리',
'욕실수리', '융자금없는', '융자금적은', '인터폰', '저층', '주방교체', '주차가능', '중층',
'천장에어컨', '총2층', '총3층', '총4층', '총5층', '탑층', '테라스', '펜트하우스', '풀옵',
'필로티', '현관보안', '화장실네개이상', '화장실두개', '화장실세개', '화장실한개', '화재경보기',
'확장형'], dtype='<U9')
# tagList내 독립적인 단어의 갯수
len(np.unique(re))
# 결과
79
원핫 인코딩 결과가 들어갈 dataframe을 제작하기 위해
(데이터 크기 x 칼럼 길이) 크기의 zeros series를 만듭니다.
zeros = np.zeros((len(tag), len(np.unique(re))))
tag내 unique한 단어를 column으로 하고 zero series를 데이터로 하는 데이터프레임을 만듭니다.
taglist = pd.DataFrame(zeros, columns = np.unique(re))
리스트 내 tag가 있으면 1.0을 더하는 형태로
원-핫 인코딩을 진행합니다.
from tqdm import tqdm
for _ in tqdm(range(len(taglist))):
for i in tag[_]:
taglist.loc[_, i] += 1.0
결과
코드의 결과는 다음과 같습니다.
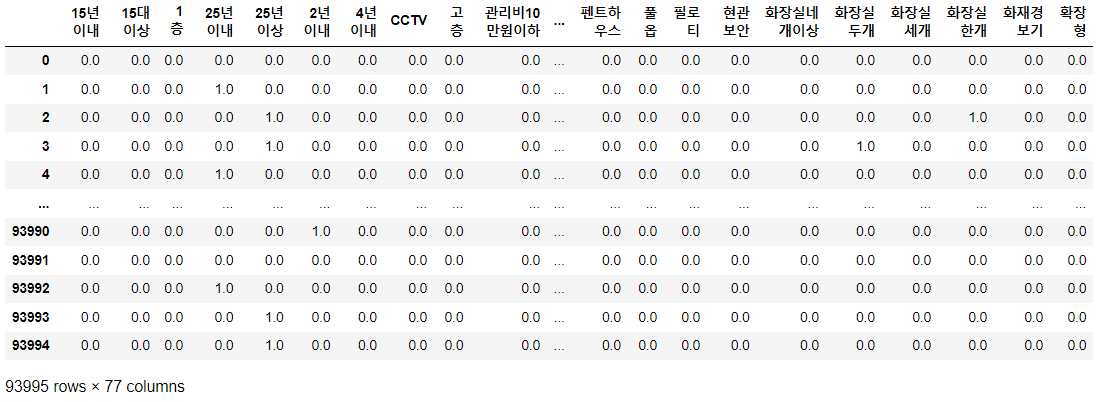
리스트 내 태그에 따라 원-핫 인코딩이 정상적으로 이루어져 있습니다.
# CSV 저장
taglist.to_csv('/assets/images/basics/tagList.csv', index = False)
댓글남기기